
实验 3 HBase、Hive 的安装与使用 更新日期:2016-5-5
1. 实验要求
本次实验所有任务都在小组第一次实验安装的自己的本地 Hadoop 环境进行。 实验任务
1. 在自己本地电脑上正确安装和运行 HBase 和 Hive。
2. 在 HBase 中创建一张表 Wuxia,用于保存下一步的输出结果。
3. 修改第 2 次实验的 MapReduce 程序,在 Reduce 阶段将倒排索引的信息通过文件输出,
而每个词语及其对应的“平均出现次数”信息写入到 HBase 的表“Wuxia”中。
4. 编写 Java 程序,遍历上一步中保存在 HBase 中的表,并把表格的内容(词语以及平均
出现次数)保存到本地文件中。
5. Hive 安装完成后,在 Hive Shell 命令行操作创建表(表名:Wuxia(word STRING, count
DOUBLE))、导入平均出现次数的数据、查询(出现次数大于 300 的词语)和前 100 个出 现次数最多的词。
输出格式
1. 请在实验报告中附上用于展示上述每一步操作结果的屏幕截图(例如 HBase Shell 中 scan ‘Wuxia’的屏幕截图和 Hive Shell 相关操作的屏幕截图)。
2. 第 3 步倒排索引的输出格式同第 2 次实验(“平均出现次数”不用输出)。
3. 第 4 步的输出格式为:“词语 \TAB 平均出现次数”。请节取部分输出内容附在报告中。
选做内容
该部分内容不做要求,供学有余力的同学尝试练习。 1.本次实验额外提供了一份停词表。先将停词表导入到 HBase 中。在进行实验任务的第 3 步 时,在 Map 阶段查询 Hbase 中的停词表,并对停用词进行过滤(不对停用词进行统计)。
2. 实验数据
本次实验提供了金庸、梁羽生等五位小说家的作品全集作为第 3 步的输入数据。每部小说对 应一个文本文件。
文本文件均使用 UTF-8 字符编码,并且已分词,两个汉语单词之间使用空格分隔。 停词表也为 UTF-8 编码,每个词语占用一行。
全部数据集:全部数据集请从集群的 HDFS 上下载,并导入到自己的本地环境中。
InvertIndex.java
package org.apache.hadoop.count;
/**
* Created by xiaopeng on 16/5/9.
*/
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Random;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class InvertIndex {
public static int FileNum = 0;
public static Configuration conf1 = null;
static {
conf1 = HBaseConfiguration.create();
// conf.set("hbase.zookeeper.quorum", "node1");
// conf.set("hbase.zookeeper.property.clientPort", "2181");
}
public static List
public static FileWriter fw = null;
public static class InvertedIndexMap extends Mapper
private Text valueInfo = new Text();
private Text keyInfo = new Text();
private FileSplit split;
public void map(Object key, Text value,Context context)
throws IOException, InterruptedException {
//获取
split = (FileSplit) context.getInputSplit();
StringTokenizer stk = new StringTokenizer(value.toString());
HTable table = new HTable(conf1, "stop");
while (stk.hasMoreElements()) {
//key值由(单词:URI)组成
Text word = new Text();
word.set(stk.nextToken());
//word.set("千万");
boolean find = false;
Get g = new Get(Bytes.toBytes(word.toString()));
Result r=table.get(g);
for (KeyValue kv: r.raw()) {
if(word.toString().equals(new String(kv.getRow()))) {
//System.out.println("!!!!!!!!!!!!!!!!!!!!!!!!");
find = true;
}
}
if(find)
{
continue;
}
keyInfo.set(word.toString()+":"+split.getPath().toString());
//词频
valueInfo.set("1");
context.write(keyInfo, valueInfo);
}
}
}
public static class InvertedIndexCombiner extends Reducer
Text info = new Text();
public void reduce(Text key, Iterable
throws IOException, InterruptedException {
int sum = 0;
for (Text value : values) {
sum += Integer.parseInt(value.toString());
}
int splitIndex = key.toString().indexOf(":");
//重新设置value值由(URI+:词频组成)
info.set(key.toString().substring(splitIndex+1) +":"+ sum);
//重新设置key值为单词
key.set(key.toString().substring(0,splitIndex));
context.write(key, info);
}
}
public static class InvertedIndexReduce extends Reducer
private Text result = new Text();
public void reduce(Text key, Iterable
throws IOException, InterruptedException {
//生成文档列表
String fileList = new String();
int sum = 0;
int times = 0;
for (Text value : values) {
String temp = value.toString();
String [] str = temp.split(System.getProperty("file.separator"));
String [] str2 = temp.split(":");
String [] str1 = str[str.length - 1].split("\\.");
sum += Integer.parseInt(str2[str2.length - 1]);
String name = "";
for (int i = 0; i < str1.length -2; i++) {
name += str1[i];
}
fileList += name + ":" + str2[str2.length - 1] + "; ";
times ++;
}
double average = (double)sum / (double)times;
Put put = new Put(Bytes.toBytes(key.toString()));
put.add(new String("apptimes").getBytes(), new String("times").getBytes(), new String(Double.toString(average)).getBytes());
putList.add(put);
fw.write(key + "\t" + fileList + "\n");
String atemp = Double.toString(average)+ ", " + fileList;
result.set(atemp);
context.write(key, result);
}
}
public static class InvertIndexSortMapper extends Mapper
private Text key = new Text();
private FileSplit split;
public void map(Object key, Text value, Mapper.Context context)
throws IOException, InterruptedException {
split = (FileSplit) context.getInputSplit();
StringTokenizer stk = new StringTokenizer(value.toString());
String name = stk.nextToken()+ " ";
String temp = stk.nextToken().toString();
String [] a = temp.split(",");
while(stk.hasMoreTokens()) {
name = name + stk.nextToken().toString() + " ";
}
double count = Double.parseDouble(a[0]);
context.write(new DoubleWritable(count), new Text(name));
}
}
public static class DoubleWritableDecreasingComparator extends DoubleWritable.Comparator {
public int compare(WritableComparable a, WritableComparable b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1,s1,l1,b2,s2,l2);
}
}
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
File f = new File("Daopai.txt");
fw = new FileWriter(f);
FileSystem fs = FileSystem.get(conf);
FileStatus[] inputFiles = fs.listStatus(new Path(args[0]));
FileNum = inputFiles.length;
Job job = new Job(conf,"InvertedIndex");
conf1 = HBaseConfiguration.create();
job.setJarByClass(InvertIndex.class);
Path tempDir = new Path("count-temp-" + Integer.toString(new Random().nextInt(Integer.MAX_VALUE)));
try {
job.setMapperClass(InvertedIndexMap.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setCombinerClass(InvertedIndexCombiner.class);
job.setReducerClass(InvertedIndexReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, tempDir);
if (job.waitForCompletion(true)) {
HBaseAdmin admin = new HBaseAdmin(conf1);
if(admin.tableExists("wuxia"))
{
admin.disableTable("wuxia");
admin.deleteTable("wuxia");
}
HTableDescriptor tableDesc = new HTableDescriptor("wuxia");
tableDesc.addFamily(new HColumnDescriptor("apptimes"));
admin.createTable(tableDesc);
HTable table = new HTable(conf1,"wuxia");
table.put(putList);
// Job sortJob = new Job(conf, "sort");
// sortJob.setJarByClass(InvertIndex.class);
// FileInputFormat.addInputPath(sortJob, tempDir);
// FileOutputFormat.setOutputPath(sortJob, new Path(args[1]));
// sortJob.setSortComparatorClass(DoubleWritableDecreasingComparator.class);
// sortJob.setMapperClass(InvertIndexSortMapper.class);
// sortJob.setMapOutputKeyClass(DoubleWritable.class);
// sortJob.setMapOutputValueClass(Text.class);
// sortJob.setOutputKeyClass(DoubleWritable.class);
// sortJob.setOutputValueClass(Text.class);
// System.exit(sortJob.waitForCompletion(true) ? 0 : 1);
}
}
finally {
//FileSystem.get(conf).deleteOnExit(tempDir);
}
}
}
scanWuxiaTable.java
package org.apache.hadoop.count;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import java.io.FileWriter;
import java.io.IOException;
import java.io.File;
/**
* Created by jiangchenzhou on 16/5/8.
*/
public class scanWuxiaTable {
private static Configuration conf = null;
private static FileWriter fileWriter = null;
static {
conf = HBaseConfiguration.create();
// conf.set("hbase.zookeeper.quorum", "node1");
// conf.set("hbase.zookeeper.property.clientPort", "2181");
}
public static void main(String[] args) throws IOException {
File f = new File("wuxia.txt");
fileWriter = new FileWriter(f);
HTable table = new HTable(conf, "wuxia");
Scan s = new Scan();
ResultScanner ss = table.getScanner(s);
try {
for (Result r: ss) {
for (KeyValue kv: r.raw()) {
System.out.print("row:; " + new String(kv.getRow()) + " ");
System.out.print("family: " + new String(kv.getFamily()) + " ");
System.out.print("qualifier: " + new String(kv.getQualifier()) + " ");
System.out.println("value: " + new String(kv.getValue()));
fileWriter.write(new String(kv.getRow()) + "\t");
fileWriter.write(new String(kv.getValue()) + "\n");
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
invertstopword.java
package org.apache.hadoop.count;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.rest.protobuf.generated.ScannerMessage;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.mapreduce.Job;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.util.*;
/**
* Created by xiaopeng on 16/5/10.
*/
public class invertstopword {
private static Configuration conf1 = null;
private static FileWriter fileWriter = null;
public static List
static {
conf1 = HBaseConfiguration.create();
// conf.set("hbase.zookeeper.quorum", "node1");
// conf.set("hbase.zookeeper.property.clientPort", "2181");
}
public static void main(String[] args) throws IOException {
File targeFile = new File("Stop_words.txt");
Scanner input = new Scanner(targeFile);
try {
while(input.hasNext())
{
//double average = (double)sum / (double)times;
Put put = new Put(Bytes.toBytes(input.nextLine().toString()));
//put.add(new String("name").getBytes());
//put.add
put.add(new String("name").getBytes(), new String("times").getBytes(), put.toString().getBytes());
putList.add(put);
}
//Configuration conf = new Configuration();
//conf1 = HBaseConfiguration.create();
HBaseAdmin admin = new HBaseAdmin(conf1);
if(admin.tableExists("stop"))
{
admin.disableTable("stop");
admin.deleteTable("stop");
}
HTableDescriptor tableDesc = new HTableDescriptor("stop");
tableDesc.addFamily(new HColumnDescriptor("name"));
admin.createTable(tableDesc);
HTable table = new HTable(conf1,"stop");
table.put(putList);
} catch (Exception e) {
e.printStackTrace();
}
}
}
报告及参考:
1 Hbase 和 Hive 的安装和运行 1.1 Hbase安装
首先,在 Hbase 官网上下载 1.1.4 版本的 Hbase,将其在 hadoop 用户下解压,对 Hbase 中的配置文件进 行修改配置。这里,最开始配置时在网上查找了很多资料,但有些资料并不适用,最后才发现官网上 供的 quick start 教程里已经讲解的非常详细,按照官网进行配置即可。首先,修改 hbase-site.xml 中的配置与 hadoop 相连,之后修改 hbase-env.sh 中 java 路径的设置。完成这两项修改之后,使用命令./bin/start-hbase.sh 进行启 动,看到 starting zookeeper,starting master 等信息即启动成功。再使用命令./bin/hbase shell 开启 hbase 的 shell 模式,在里面可以用简单的语句对数据库进行测试,不出现问题即配置成功。
1.2 Hive安装
首先,在 Hive 官网上下载 2.0.0 版本的 Hive,将其在 hadoop 用户下解压,Hive 的配置相对简单,不需 要修改配置文件即可使用,只需要在使用前初始化 Hive 的默认数据库 derby,初始化命令如下:./bin/schematool –dbType derby –initSchema。初始化成功后,使用命令./bin/Hive 即可启动 Hive。
(注:Hbase 和 Hive 启动时都需要开启 Hadoop,使其满足运行环境) 2 Hbase 中创建表格
这里没有在 hbase 中手动创建,而是将创建表格的功能在代码中进行了实现,所以具体细节将在下面进 行介绍。
注意:一定要按照官方文档安装,blog什么的都不咋靠谱。我这里使用的是hadoop2.7.1在不同机器上的安装几本稳定了。我使用的是mac版,注意安装时,确定没有因为联网等问题造成绝对路径的修改。另外,intellij idea可以直接运行hadoop程序,调用hbase需要加入hbase文件下的lib文件夹下所有jar包,链接hbase需要hadoop hbase等进程开启。
关于hadoop安装,可以参考
hadoop安装参考
3 将实验2的输出结果保存入Hbase
这里我们在实现时对实验 2 的代码进行了修改,代码中添加了数据库的创建,删除和插入数据的功能, 每次创建数据库时会首先检查是否含有名为‘wuxia’的表,如果有则想起删除,再新建一个表,这样可以避 免程序运行时报错,也减少了手动删除数据库的工作量。代码实现方面,HBaseConfiguration 类用来对 Hbase 进行配置,HbaseAdmin 类可以用来创建和删除一个表格,put 类可以用来向表格中插入数据,在了解函数功 能之后,实现起来还是比较简单的。实验结果部分截图如下:
2
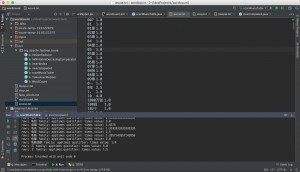
图 1 wuxia 在 Hbase 中存储结果 4 遍历表格,将表格中内容保存到本地文件
这个任务则更加简单,只需要在创建 Hbase 配置之后,利用 scan 类对表格进行扫 ,将扫 得到的数据 库中每一行的数据进行 取,将词语和出现次数输入到文件当中即可。结果的部分截图如下:
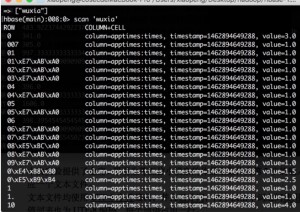
图 2 表格内容输出到文件 5 在Hiveshell中导入上面的输出文件,并进行查询操作
在 Hive 中查询语句基本与之前使用过的 mysql 语句类似,所以在将数据导入到表格中后,可以比较容易 的查询到想要的内容。
5.1 导入平均出现次数的数据
在 Hive 中利用语句:LOAD DATA LOCAL INPATH ‘本地文件路径’INTO TABLE ‘表格名’;来进
行数据的导入,导入之后可以使用“select * from 表格名”来进行查询,查询结果部分截图如下:
3
![@VD)@V$[6R2QBST_U(]4]Y7](http://www.seckinesis.com/wp-content/uploads/2016/05/@VD@V6R2QBST_U4Y7-300x218.jpg)
图 3 Hive 中所有数据查询结果
4
5.2 查询出现次数大于300的词语
5.3 查询前100个出现次数最多的词语
利用 DESC 语句倒序排序,可以列出数据库中前 100 的数据,结果部分截图如下:
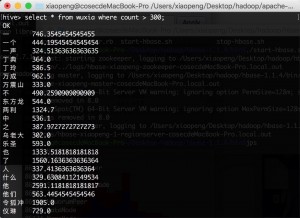
图4 大于300的结果
图 5 前 100 个出现次数最多的词语
(1)查询所有数据:
5
6 选做部分实现
基本实现思路也是在原有代码的基础上进行添加修改,首先在 main 函数中创建一个 hbase 数据库表格, 将停词表的内容存放进去,然后每一次 map 都会在停词表中进行查找,如果包含该词则不会进行下面的 reduce 工作,之后所进行的操作基本不变,将输出结果再保存到 hive 当中,供随时查询即完成任务。
下面是 hive 中的保存内容的查询结果部分截图,从图中的一些查询结果与上面的结果对比可以看出得到 的结果已经不再包含停词表中的内容,任务完成。
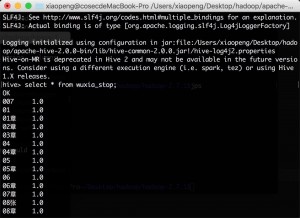
图 6 查询所有数据
6
(2)查询出现次数大于 300 的词语:
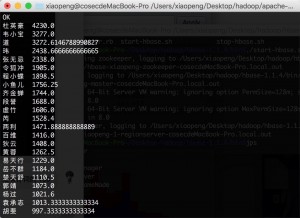
图 7 查询出现次数大于 300 的词语
(3)查询前 100 个出现次数最多的词语
图 8 查询前 100 个出现次数最多的词语
所有工程资料可以在github上下载,欢迎交流学习。
数据资料及测试数据等